SVM, the Kernel Trick, and the Gaussian Process
SVMs, support vector machines, are for using a (d-1) dimensional linear divider for classifying 2 classes in a d-dimensional space. It maximizes the distance between the two categories, called a margin. The boundary data points (on the margin on each side, i.e. the points closest to each other that are still classified differently) are called the support vectors (when drawing an orthogonal to the middle division boundary)
It's a convex optimization problem subject to constraints where each class must be on the correct side of the decision boundary. Due to it's simplicity, though, we might need the kernel trick. For non-linear decision boundaries, we can augment the data by projecting it into a higher dimensional space and creating a 'linear' decision boundary there, before projecting the points back to the original space. This effectively creates a nonlinear decision boundary while still using the traditional SVM process.
However, it gets expensive to project into higher dimensions (working with data with many more features), so we can make use of the kernel trick. 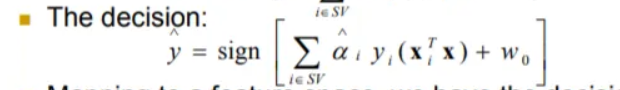
(tangent:
To classify each point, we only work with the dot product of data points, not the actual data points themselves. Therefore, instead of storing each
Gaussian Process
To fit a curve to a set of data points, there are an infinite number of functions we can choose. The Gaussian Process is a probability distribution over a set of plausible functions for a set of data points. We update the Gaussian with each data point we see by using conditional functions
The kernel of a GP stores the covariance of all input points, which encodes their similarity. It only depends on the inputs (x's), not the output labels (y's). The kernel is used in the mean function and calculating uncertainty of your predictions. You pick a kernel based on the prior belief based on your belief about what the best-fit function should look like, and this kernel guides the set of 'plausible functions' that the probability distribution is over (e.g. Polynomial
my notes on lecture 25 of my [introductory ML course][https://www.cs.cmu.edu/~10701-s26/index.html#Home]